数据压缩 ⭐️⭐️
文件压缩有两大好处:
- 减少存储文件所需要的磁盘空间
- 加速数据在网络和磁盘上的传输
通过一定的算法对数据进行特殊编码,使得数据存储的空间更小,此过程称为压缩,反之为解压缩。
更多内容可参考:
http://wiki.dsbigdata.com/pages/viewpage.action?pageId=34224101
1.Hadoop支持的压缩格式
| 压缩格式 | Hadoop自带 | 算法 | 文件拓展名 | 是否可切分 |
|---|---|---|---|---|
| DEFLATE | 是 | DEFLATE | .deflate | 否 |
| Gzip | 是 | DEFLATE | .gz | 否 |
| bzip2 | 是 | bzip2 | .bz2 | 是 |
| LZO | 否 | LZO | .lzo | 是 |
| Snappy | 否 | Snappy | .snappy | 否 |
压缩的关键:
- 压缩工具通常需要在时间和空间之间进行权衡。较长的压缩时间通常意味着压缩率更高,占用的空间更少;而较短的压缩时间则通常意味着压缩率较低,占用的空间较大。
- Hadoop中,特别需要考虑压缩文件的可分割性,它会影响到在执行作业时Map启动的个数,从而会影响到作业的执行效率。
- Hadoop可以自动识别压缩格式。如果压缩文件具有相应压缩格式的扩展名(如lzo、gz、bzip2等),Hadoop会根据扩展名自动选择相应的解码器来解压数据。
压缩算法性能比较(摘自ABM):
| 压缩算法 | 测试文件原始大小 | 压缩后文件大小 | 压缩速度 | 解压缩速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
| LZO-bset | 8.3GB | 2GB | 4MB/s | 60.6MB/s |
Hadoop 的压缩 codec:
| 压缩格式 | HadoopCompressionCodec |
|---|---|
| DEFLATE | org.apachehadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
2.压缩的使用阶段
Map输入阶段:
在Map输入端压缩时,可以使用压缩文件作为Map的输入数据,无需显式指定编解码方式,Hadoop会自动检查文件扩展名,并选择合适的编解码方式对文件进行压缩和解压。
Map输出阶段:
在Map输出端压缩时,可以考虑使用压缩来减少Shuffle阶段中网络传输的数据量,从而提高性能。这可以通过在Map阶段输出数据时进行压缩来实现。压缩后的数据将在Shuffle阶段传输,并在Reduce节点上解压缩。
Reduce输出阶段:
在Reduce端输出时,可以选择对输出的结果数据进行压缩。这样可以减少存储的数据量,降低所需磁盘空间的使用。另外,如果输出数据作为第二个MapReduce作业的输入,压缩后的数据可以被复用,进一步提高性能。
3.如何使用压缩
代码层面
当我们需要自定义某个mapreduce任务是否需要开启压缩的时候,可以基于代码的driver类通过Configuration来直接设置。
// 定义配置文件对象
Configuration conf = new Configuration();
// ========================
// 配置 Map 输出的压缩
// ========================
conf.set("mapreduce.map.output.compress", "true");
conf.set("mapreduce.map.output.compress.codec", "org.apache.hadoop.io.compress.SnappyCodec");
/*
* 参数说明:
* mapreduce.map.output.compress
* 设置为 "true" 表示启用 Map 输出的压缩。
*
* mapreduce.map.output.compress.codec
* 指定使用 SnappyCodec 作为压缩编解码器。
*/
// ========================
// 配置 Reduce 输出的压缩
// ========================
conf.set("mapreduce.output.fileoutputformat.compress", "true");
conf.set("mapreduce.output.fileoutputformat.compress.type", "RECORD");
conf.set("mapreduce.output.fileoutputformat.compress.codec", "org.apache.hadoop.io.compress.SnappyCodec");
/*
* 参数说明:
* mapreduce.output.fileoutputformat.compress
* 设置为 "true" 表示启用 Reduce 输出的压缩。
*
* mapreduce.output.fileoutputformat.compress.type
* 指定压缩类型为 "RECORD",表示以记录为单位进行压缩。
*
* mapreduce.output.fileoutputformat.compress.codec
* 指定使用 SnappyCodec 作为压缩编解码器。
*/
集群层面
通过修改集群的配置参数,可以配置所有的mapreduce任务启用压缩。
vi mapred-site.xml
<configuration>
<!-- 启用 Reduce 输出压缩 -->
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
<description>启用 Reduce 输出结果的压缩</description>
</property>
<!-- 设置压缩类型为 RECORD(按记录压缩) -->
<property>
<name>mapreduce.output.fileoutputformat.compress.type</name>
<value>RECORD</value>
<description>以记录为单位进行压缩</description>
</property>
<!-- 指定压缩编解码器为 Snappy -->
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description>使用 SnappyCodec 作为压缩编解码器</description>
</property>
</configuration>
4.压缩案例应用
基于上面的wordcount案例的基础,添加map和reduce阶段的压缩设置。
设置作业中启用 map 任务输出 gzip 压缩格式;
//配置Reduce输出的压缩
conf.set("mapreduce.output.fileoutputformat.compress","true");
conf.set("mapreduce.output.fileoutputformat.compress.type", "RECORD");
conf.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.GzipCodec");
输出结果:
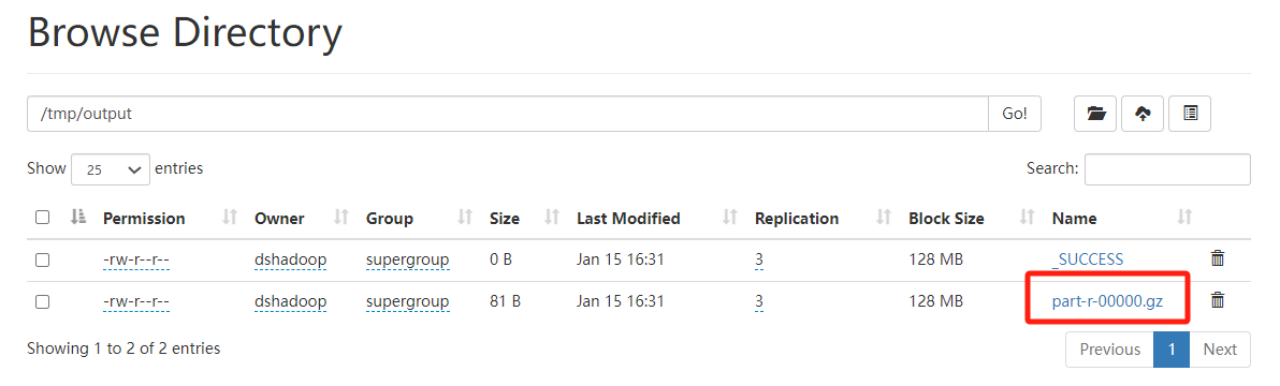
5.Hive 压缩
hive对表存储设置压缩,如snappy,snappy不支持split,所以导致map端无法切分文件,只有一个map task。 是因为 hive中表设置了压缩存储后,后续的读取使用,不需要解压缩吗。如果会解压,为何如snappy这种格式map端会因为无法切分导致只有一个map task。
在Hive中对表进行压缩存储设置后,读取数据时确实不需要进行解压缩操作,这是因为Hive可以直接在压缩格式下进行读取和查询。所以snappy无法切片并不是因为不支持解压缩,同样解压缩,而是它的压缩方式比较怪;
snappy格式的文件在HDFS中并不支持数据的切分。Hadoop默认的切分方式是基于文件的字节偏移量进行切分,而Snappy格式的文件并不是按照字节偏移量进行切分的,而是按照压缩块进行切分的。这就导致了无法按照默认方式切分文件,从而只能使用一个Map Task来处理整个文件。
为啥叫不可切分啥意思?
1、假设有一个1GB的不压缩的文本文件,如果HDFS的块大小为128M,那么该文件将被存储在8个块中,把这个文件作为输入数据的MapReduc/Spark作业,将创建8个map/task任务,其中每个数据块对应一个任务作为输入数据。
对于不压缩的文本文件来说,是可切分,因为每个block都存了完整的数据信息,读取的时候可以按照规定的方式去读:比如按行读。
2、假如一个文本文件经过snappy压缩后,文件大小为1GB。与之前一样,HDFS也是将这个文件存储成8个数据块。但是每个单独的map/task任务将无法独立于其他任务进行数据处理,官方一点的说法,原因就是压缩算法无法从任意位置进行读取。
通俗的讲解,就是因为存储在HDFS的每个块都不是完整的文件,我们可以把一个完整的文件认为是具有首尾标识的,因为被切分了,所以每个数据块有些有头标示,有些有尾标示,有些头尾标示都没有,所以就不能多任务来并行对这个文件进行处理。
粗暴点来讲,就是因为经过snappy压缩后的文本文件不是按行存了,但是又没有相关的结构能记录数据在每个block里是怎么存储的,每行的起止位置在哪儿,所以只有将该文件的所有HDFS的数据块都传输到一个map/task任务来进行处理,但是大多数数据块都没有存储在这个任务的节点上,所以需要跨节点传输,且不能并行处理,因此运行的时间可能很长。
对比案例: