序列化和反序列化
面试问的概率不是很大,了解即可
序列化和反序列化概念
序列化(Serialization)
序列化是指将数据结构或对象状态信息转换成可以存储或传输的格式的过程。在Hadoop的中,是指将内存中的对象(如MapReduce任务中的键值对)转换为字节流,以便在网络中传输或者在HDFS中存储。这个过程使得对象的状态可以在不同的Java虚拟机(JVM)之间共享,是Hadoop实现其分布式计算和数据共享的关键部分。
反序列化(Deserialization)
反序列化是序列化的逆过程,即将字节流转换回内存中的对象。在Hadoop中,这通常发生在数据从HDFS读取到内存中,或者在MapReduce作业的不同任务之间通过网络传输后。反序列化使得这些字节流可以被重新构造为Java对象,从而可以在程序中直接使用。
序列化的作用:
(1)一种持久化的格式:将将对象序列化后,把字节存到磁盘上;
(2)一种通信数据格式:进行网络传输,比如从一个虚拟机传到另一个虚拟机;
(3)一种拷贝和克隆的机制:用于深拷贝。
Hadoop中一般作用是前两种。
Java序列化
一个类只要实现了serializable(序列化接口),就可以进行序列化了。但是serializable只是一个标识,没有具体方法,只是判断一类是否可以序列化。
实现:创建一个ObjectOutputStream对象,这个对象指示序列化写入的地方,然后调用writeObject()方法,进行序列化写入。
�如果存在继承问题,父类实现序列化接口,则子类自动实现;若子类实现了序列化,父类没有实现,则父类需要一个无参构造器,子类将负责序列化父类的域。
序列化结果中包含了大量与类相关的信息导致结果膨胀,所以对于Hadoop来说需要新的序列化机制。
Hadoop序列化
Hadoop采用序列化接口Writable。可实现对基本数据类型进行序列化和自定义对象序列化。RawComparator接口允许在数据流中比较大小,不用反 序列化,节省开销,是在每个基本类型封装器中通过静态内部类实现的,比如IntWritable内部类Comparator继承了WritableComparator类(RawComparator接口一个通用实现),可在数据流中比较大小。
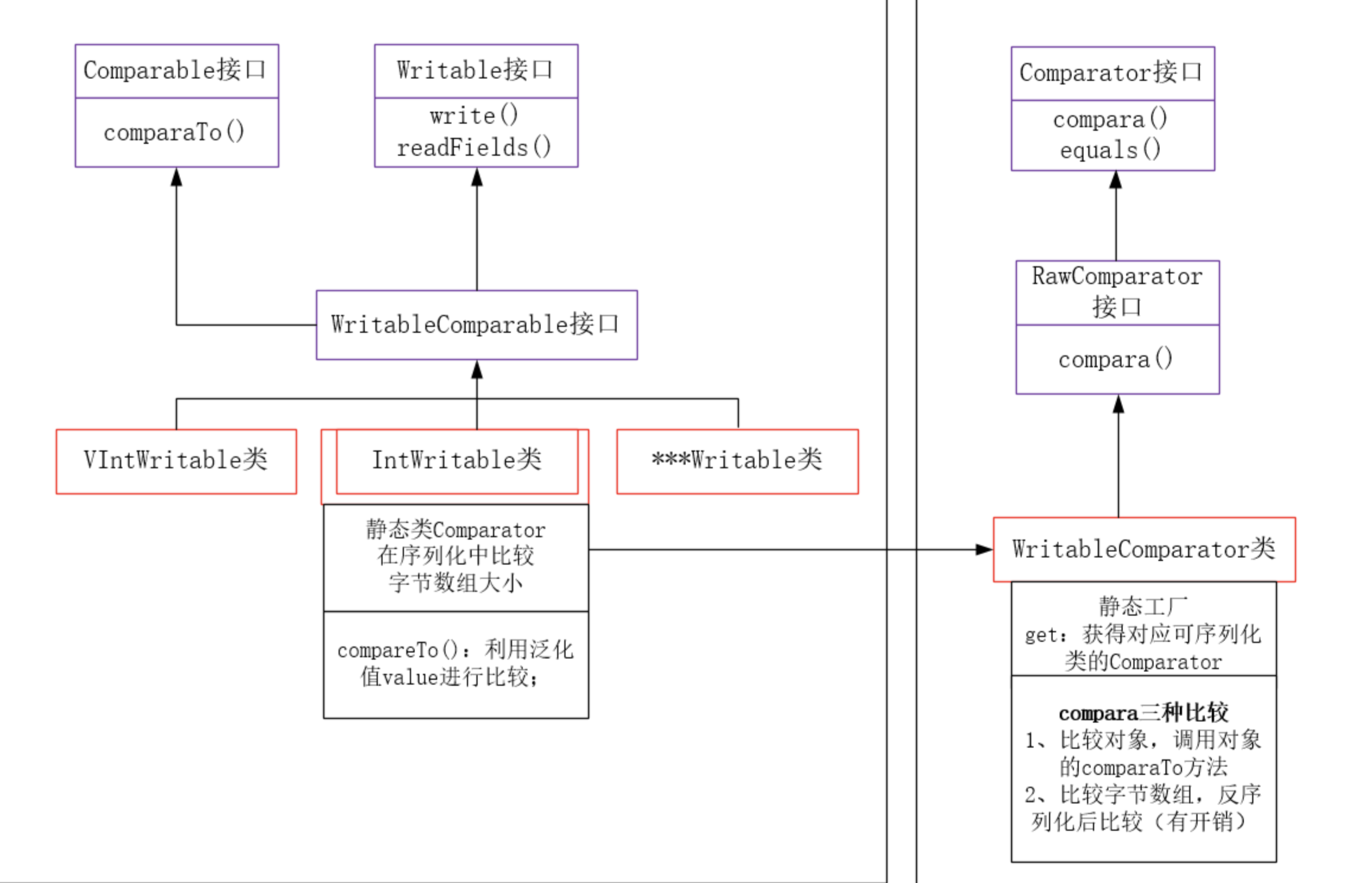
java序列化机制和Hadoop序列化比较
Hadoop序列化框架相比较优势在于:
(1)绝对紧凑:序列化后数据更加紧凑,节省带宽。
(2)快速快:尽量避免减小序列化和反序列化的开销。