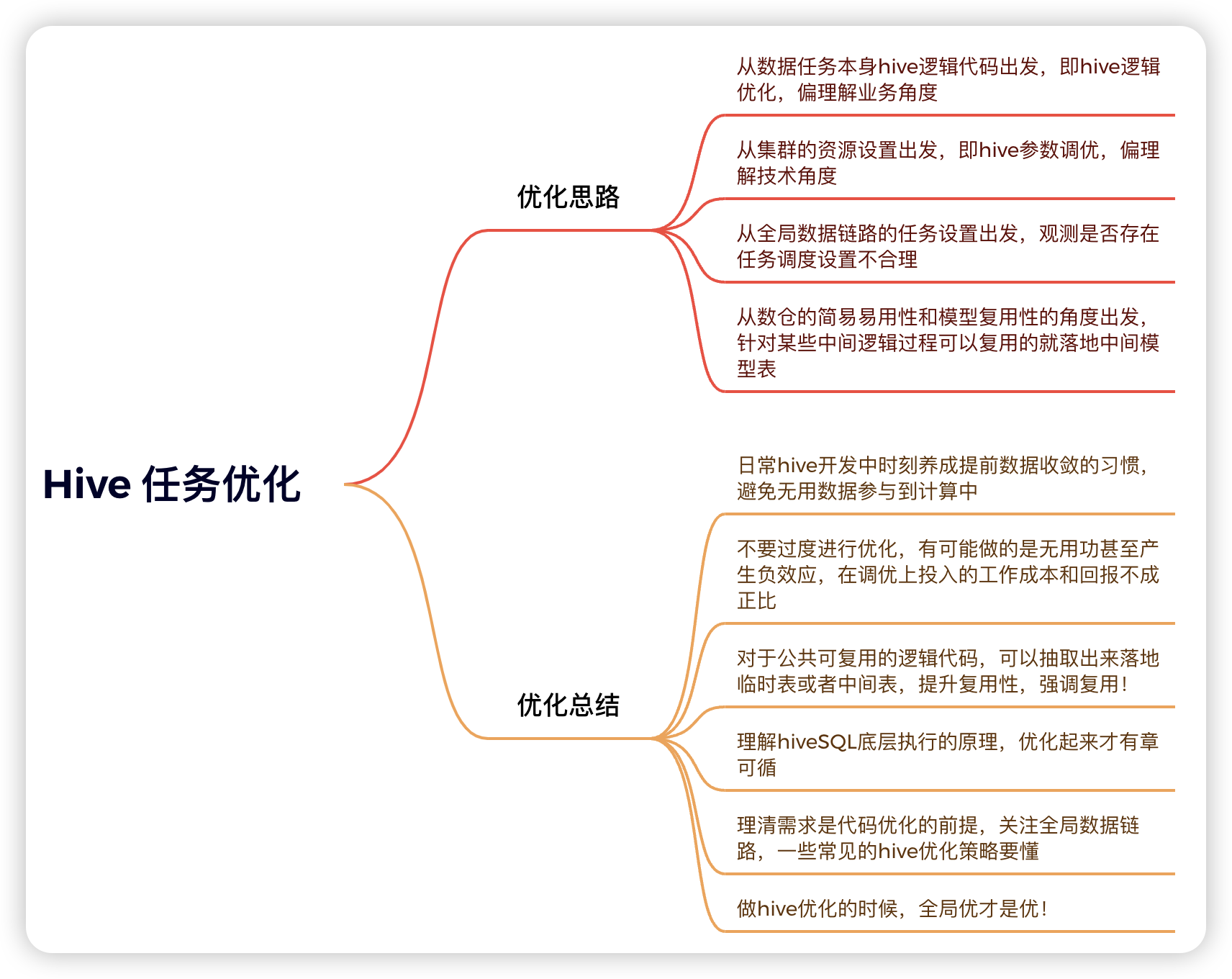
Hive任务优化总览 ⭐️⭐️⭐️
一、引言
在Hive离线数仓的日常开发中,一个设计良好的数据任务,其运行时长应在可预期的合理范围内。然而,当报表层数据频繁出现产出延迟,经排查发现某些核心任务执行耗时超过10小时,这显然是不合理的。此时,我们必须对数据任务链路进行系统性优化。本文将从以下四个核心角度,深入探讨Hive任务的优化策略与实践:
- HiveQL逻辑优化:从数据任务本身的SQL逻辑出发,结合业务理解,进行代码层面的优化。
- 数据模型优化:从数仓的数据易用性和模型复用性出发�,将可复用的中间逻辑固化为中间表,减少重复计算。
- Hive参数调优:从集群资源配置和Hive执行引擎的角度出发,进行技术参数的精细化调整。
- 任务调度优化:从全局数据链路的任务依赖和执行时机出发,审视并调整任务调度的合理性。
为了更直观地展示优化体系,以下是本文所涉及核心知识点的思维导图概览。
二、Hive 性能优化详解
本文将围绕以下11个关键点展开详细论述:
- 列裁剪和分区裁剪
- 提前进行数据收敛
- 谓词下推 (Predicate Pushdown, PPD)
- 多路输出,减少源表扫描次数
- 合理选择排序策略
- Join 关联优化
- 合理选择文件存储格式与压缩方式
- 解决小文件过多问题
COUNT(DISTINCT)与GROUP BY的抉择- 核心参数调优
- 解决数据倾斜问题
1. 列裁剪和分区裁剪
裁剪的核心思想是:只读取任务所需的��最少数据,从源头上避免不必要的I/O开销。
- 列裁剪 (Column Pruning):在查询时应明确指定所需的列名,坚决避免使用
SELECT *。SELECT *不仅降低了代码的可读性,更重要的是,它会读取所有列的数据,即使下游计算并未使用,从而极大地增加了网络I/O和内存消耗。 - 分区裁剪 (Partition Pruning):对于分区表,务必在
WHERE子句中指定明确的分区过滤条件。Hive执行计划会根据分区条件,仅扫描指定分区的数据,跳过无关分区,这是Hive查询性能优化的第一道防线。
2. 提前进行数据收敛
在多层嵌套的SQL查询中,应尽早地过滤掉无效数据。如果一个过滤条件不依赖于后续的JOIN或聚合操作,就应该将其前置到最内层的子查询中,以减少中间结果集的数据量。
-- 原始脚本
SELECT
a.字段a, a.字段b, b.字段a, b.字段b
FROM
(
SELECT 字段a, 字段b
FROM table_a
WHERE dt = date_sub(current_date, 1)
) a
LEFT JOIN
(
SELECT 字段a, 字段b
FROM table_b
WHERE dt = date_sub(current_date, 1)
) b
ON a.字段a = b.字段a
WHERE a.字段b <> ''
AND b.字段b <> 'xxx';
-- 优化脚本 (数据提前收敛)
SELECT
a.字段a, a.字段b, b.字段a, b.字段b
FROM
(
SELECT 字段a, 字段b
FROM table_a
WHERE dt = date_sub(current_date, 1)
AND 字段b <> '' -- 将过滤条件提前至子查询
) a
LEFT JOIN
(
SELECT 字段a, 字段b
FROM table_b
WHERE dt = date_sub(current_date, 1)
AND 字段b <> 'xxx' -- 将过滤条件提前至子查询
) b
ON a.字段a = b.字段a;
3. 谓词下推��(Predicate Pushdown, PPD)
谓词下推 (PPD) 是一种查询优化机制,它将WHERE子句中的过滤条件尽可能地推向靠近数据源的执行阶段(例如,在Map阶段),以提前过滤掉不满足条件的数据。这样做可以显著减少Map阶段输出到Reduce阶段的数据量,降低网络传输开销,节约集群资源,从而提升任务性能。
Hive默认开启谓词下推:set hive.optimize.ppd=true;
所谓下推,即谓词过滤在Map端执行;所谓不下推,即谓词过滤在Reduce端执行。其下推规则与JOIN类型密切相关,核心判断逻辑是:下推操作不能改变JOIN的原始语义。
| 子句 | 条件针对的表 | 核心作用 | 对左表行的影响 | 是否可下推 |
|---|---|---|---|---|
| ON | 左表 | 匹配规则 | 决定左表行是否有资格参与匹配 | 可以 |
| ON | 右表 | 匹配规则 | 决定左表行与右表行是否能配对成功 | 不可以 |
| WHERE | 左表 | 最终过滤器 | 最终筛选左表行,不符合就丢弃 | 可以 |
| WHERE | 右表 | 最终过滤器 | 会错误地过滤掉左表中未匹配成功的行(因为其右表字段为NULL) | 绝对不可以 |
核心判断逻辑:
- ON 子句 = “匹配规则”
- 它的工作发生在 Join的过程中。
- 它告诉Hive:“请帮我从左表里拿出一行,然后按照这个规则去右表里找对象。找到了,就把它们拼在一起;如果按这个规则找不到,也没关系,左表的这行我还要,只是右边对应的位置填上NULL就行。”
- 核心:ON子句只决定右表能不能“配对成功”,但 绝不 影响左表的行是否要出现在中间结果里。
- WHERE 子句 = “最终过滤器”
- 它的工作发生在 Join过程完全结束之后。
- 它拿到LEFT JOIN生成的、包含NULL值的完整结果集,然后说:“好了,现在我们按这个最终规则筛选一遍,不满足的通通扔掉。”
- 核心:WHERE子句是对已经生成的结果进行“生杀予夺”,它 会 过滤掉最终不符合条件的行,哪怕这些行来自于我们想保留的左表。
-- 举例说明:以下脚本 on后面的a表条件过滤没有下推至map端运行而是在reduce端运行,where后面的b表条件过滤则有下推至map端运��行
SELECT
a.字段a, a.字段b, b.字段a, b.字段b
FROM
table_a a
LEFT JOIN
table_b b
ON
a.字段a <> '' -- a表条件过滤
-- [此条件不能下推至Map端]
-- 原因: 这是一个JOIN的“匹配规则”,而非“预过滤条件”。
-- LEFT JOIN的语义要求保留所有左表(a)的行。如果某行`a.字段a = ''`,
-- 它只是根据此规则匹配失败,但该行本身必须出现在最终结果里(对应的b表字段为NULL)。
-- 如果下推,这些行会在Map端被错误地提前丢弃,从而破坏了LEFT JOIN的语义。
-- 因此,它必须在Reduce端的JOIN过程中执行。
WHERE
a.字段b <> 'xxx' -- a表条件过滤
-- [此条件可以下推至Map端]
-- 原因: 这是一个作用于JOIN最终结果的“过滤规则”。
-- 任何不满足`a.字段b <> 'xxx'`的行,无论JOIN是否成功,最终都将被丢弃。
-- 因此,将此过滤操作提前到Map端对a表进行,是一种安全的优化,
-- 它能有效减少进入Reduce阶段的数据量,且不会改变最终的查询结果。
;
谓词下推注意事项:
如果过滤表达式中包含不确定性函数(如 rand(), unix_timestamp()),整个表达式的谓词将不会被下推。因为在编译阶段无法确定其值,优化器无法保证下推的安全性。
SELECT *
FROM a JOIN b ON a.id = b.id
WHERE a.ds = '2019-10-09'
AND a.create_time = unix_timestamp(); -- 由于unix_timestamp()是不确定性函数
-- 整个WHERE子句都不会被下推,包括 a.ds = '2019-10-09' 这个条件
4. 多路输出
当需要基于同一个源表,通过不同的计算逻辑,将结果插入到多个目标表或分区��时,应使用多路输出(Multi-Insert)。这样只需扫描一次源表,即可完成多次插入,避免了对源表的重复读取,显著提升性能。
-- 未优化写法:扫描源表两次
-- 任务1
INSERT INTO TABLE stu1 PARTITION(dt='dt1')
SELECT MAX(s_birth)
FROM stu_ori
GROUP BY s_age;
-- 任务2
INSERT INTO TABLE stu2 PARTITION(dt='dt2')
SELECT MIN(s_birth)
FROM stu_ori
GROUP BY s_age;
-- 优化后:使用多路输出,仅扫描源表一次
-- 开启动态分区(如果目标分区是动态的)
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
FROM stu_ori
INSERT INTO TABLE stu1 PARTITION(dt='dt1')
SELECT MAX(s_birth)
GROUP BY s_age
INSERT INTO TABLE stu2 PARTITION(dt='dt2')
SELECT MIN(s_birth)
GROUP BY s_age;
注意事项:
- 一个SQL语句中最多支持128路输出。
- 当多路输出的目标是同一张表的不同分区时,不允许同时混用
INSERT OVERWRITE和INSERT INTO,必须统一操作。
5. 合理选择排序
-
ORDER BY执行全局排序,所有数据都会汇集到一个Reducer中进行处理。当数据量巨大时,极易导致Reducer内存溢出或执行超时。在Hive的严格模式下,使用ORDER BY必须配合LIMIT子句。 -
SORT BY执行局部排序,仅保证每个Reducer内部的输出数据是有序的,但不能保证全局有序。 -
DISTRIBUTE BY控制Map输出数据如何**分区(shuffle)**到Reducer。它根据指定的字段进行哈希计算,确保相同键值的数据被发送到同一个Reducer。 -
CLUSTER BYDISTRIBUTE BY和SORT BY的结合体。当分区键和排序键相同时,可以使用CLUSTER BY简化语法。但CLUSTER BY只能进行升序排序。
优化案例:从10亿用户表中,获取年龄最小的前100名用户信息。此案例体现了“分而治之”的大数据处理思想。
-- 原脚本 (性能极差)
SELECT *
FROM tmp.user_info_table
WHERE dt = '2022-07-04'
ORDER BY age -- 全局排序,仅一个Reducer,处理10亿数据,基本无法完成
LIMIT 100;
-- 优化��脚本 (分治策略)
SET mapred.reduce.tasks=50; -- 根据数据量和集群资源合理设置Reduce数量
SELECT *
FROM
(
SELECT *
FROM tmp.user_info_table
WHERE dt = '2022-07-04'
-- 按年龄段将数据分发到不同Reducer,避免数据倾斜
DISTRIBUTE BY (CASE WHEN age < 20 THEN 0
WHEN age >= 20 AND age <= 40 THEN 1
ELSE 2
END)
SORT BY age ASC -- 在每个Reducer内部进行局部排序
) t
LIMIT 100; -- 从第一个Reducer的有序输出中取前100条即可
-- 解释:
-- 1. DISTRIBUTE BY: 将数据按年龄段均匀分发到多个Reducer,避免随机分发可能导致的倾斜。
-- 2. SORT BY: 在每个Reducer内部对年龄进行排序。
-- 3. LIMIT 100: 由于数据已按年龄局部排序,我们只需从第一个Reducer的输出结果中取前100条,即可得到全局年龄最小的前100名用户。
排序选择小结:
ORDER BY:慎用,仅适用于数据量小或必须进行全局排序且已加LIMIT的场景。SORT BY:实现局部排序,常与DISTRIBUTE BY配合使用。DISTRIBUTE BY:控制数据分区,是解决数据倾斜和实现高效并行处理的关键。- 要实现全局有序且利用多Reducer,可采用两阶段排序:内层
SORT BY+ 外层ORDER BY+LIMIT。例如:`select * from (select * from 表名 sort by 字段名 limit N) order by 字段名 limit N
6. Join 优化
Hive中,Join操作是性能优化的重点区域。Join可以在Map端(Map Join)或Reduce端(Common Join)执行。
提前收敛数据量
在进行JOIN之前,务必通过WHERE子句或子查询,将无关数据过滤掉。此原则与前面的“数据收敛”和“谓词下推”一脉相承。
LEFT SEMI JOIN(左半连接)
LEFT SEMI JOIN是IN/EXISTS子查询的更高效替代方案。它的效果类似于INNER JOIN,但最终结果只返回左表的列,且对于右表中重复的匹配键,左表的一行数据只会被返回一次。
SELECT *
FROM
(
SELECT 1 AS id, 'a' AS name
UNION ALL
SELECT 2 AS id, 'b' AS name
) a
LEFT SEMI JOIN
(
SELECT 1 AS id, 'b' AS name
UNION ALL
SELECT 1 AS id, 'c' AS name
) b
ON a.id = b.id;
-- 结果:
-- id name
-- 1 a
-- 如果是INNER JOIN,结果会是
-- id name
-- 1 a
-- 1 a
LEFT SEMI JOIN 注意事项:
SELECT子句中不能出现右表的列。WHERE子句中不能引用右表的字段。- 它只关心是否存在匹配,不关心匹配次数,因此在处理右表有重复键的场景时,性能优于
INNER JOIN。
大表 Join 小表
- Map Join: 将小表加载到内存中,在Map阶段直接与大表进行Join,避免了Reduce阶段的shuffle和排序,效率极高。Hive默认会自动尝试将小表转换为Map Join。
-- 开启自动Map JoinSET hive.auto.convert.join = true;-- 设置小表的阈值,默认为25MBSET hive.mapjoin.smalltable.filesize=26214400;
- 表放置顺序: 在旧版Hive中,
JOIN操作会将左表加载到内存。因此,将小表放在JOIN左侧是推荐做法。尽管新版Hive对此有所优化,了解这一原理仍有帮助。
大表 Join 大表
当两个大表进行Join时,如果关联键存在大量NULL值或特定倾斜值,极易导致数据倾斜。
1. 空Key过滤
如果NULL值的关联键对业务无意义,应在Join前将其过滤掉。
SELECT a.id
FROM (SELECT * FROM a WHERE id IS NOT NULL) a
JOIN b ON a.id = b.id;
2. 空Key转换
如果NULL值的记录需要保留,可以通过随机化空Key来打散数据,避免它们被分配到同一个Reducer。
SELECT a.id
FROM a
LEFT JOIN b ON
CASE
WHEN a.id IS NULL THEN concat('hive_skew_', rand())
ELSE a.id
END = b.id;
注意:此方法虽然解决了数据倾斜,但也使得这些空值关联键失去了原有的关联意义。它适用于
LEFT JOIN且你只关心保留��左表数据,或者在聚合场景下分离倾斜键的计算。
避免笛卡尔积
严禁在JOIN时缺少ON条件或使用无效的ON条件,这会产生笛卡尔积。Hive的严格模式会禁止此类查询,直接报错。
7. 合理选择文件存储格式和压缩方式
推荐使用列式存储格式,如 ORC 或 Parquet。它们相比于行式存储(如TEXTFILE)有以下巨大优势:
- 高压缩比:列式存储的数据类型一致,更易于压缩。推荐使用
Snappy或ZSTD压缩,它们在压缩率和解压速度之间取得了良好平衡。 - I/O性能:查询时只需读取所需的列,极大减少了磁盘I/O。
- 谓词下推:ORC和Parquet格式内部存储了统计信息(如min/max值),查询引擎可以利用这些信息跳过不含目标数据的整个数据块(row group),进一步提升性能。
8. 解决小文件过多问题
小文件的产生
小文件通常在数据写入时产生,主要来源包括:
INSERT INTO ... VALUES():每次执行产生一个文件(生产环境罕见)。LOAD DATA:源文件夹中有多少文件,目标表中就产生多少文件。INSERT OVERWRITE ... SELECT ...:最常见的来源。输出文件数 = Reducer数量 * 分区数,如果说某些简单job没有reduce阶段只有map阶段,那文件数量 = Map数量 * 分区数。如果Reduce数量设置不当或任务只有Map阶段,就容易产生大量小文件。所以可以通过调整Map/Reduce的个数以及分区数达到控制Hive表的文件数量。
小文件的影响
- HDFS NameNode压力:每个文件(无论大小)都会在NameNode中产生一条元数据记录,大量小文件会耗尽NameNode的内存。
- 计算性能下降:在MapReduce模型中,每个小文件通常会启动一个Map任务。任务启动和初始化的开销远大于实际数据处理的时间,造成巨大的资源浪费。
解决方案
1. 合并已存在的小文件
使用CONCATENATE命令,但仅支持ORC或RCFile格式。
-- 对非分区表
ALTER TABLE table_name CONCATENATE;
-- 对分区表
ALTER TABLE table_name PARTITION(dt='...') CONCATENATE;
2. 通过参数在Map输入端合并(减少Map数量) 在任务执行前,通过设置参数让Hive在Map阶段的输入端自动合并小文件,从而减少启动的Map Task数量。
设置Map输入时合并小文件
-- 102400000B=102400KB=100M
-- 每个Map最大输入大小(这个值决定了合并后文件的数量)
set mapred.max.split.size=102400000;
-- 一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=102400000;
-- 一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=102400000;
-- 启用CombineHiveInputFormat来执行合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- map执行前合并小文件
-- 注释:前3行设置是确定合并文件块的大小,>128M的文件按128M切块,>100M和<128M的文件按100M�切块,剩下的<100M的小文件直接合并。
3. 通过参数在输出端合并 在任务的输出阶段(Map输出或Reduce输出)合并生成的文件,以控制最终落地的文件大小和数量。
设置Map输出和Reduce输出时合并小文件
-- 设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true;
-- 设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true;
-- 设置合并后每个文件的大小
set hive.merge.size.per.task = 256*1000*1000;
-- 当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge
set hive.merge.smallfiles.avgsize=16000000;
4. 调整Reduce数量
通过直接控制Reduce任务的数量,来间接控制输出文件的数量。配合DISTRIBUTE BY rand()可以确保数据均匀分布到每个Reducer,避免生成的文件大小差异过大。
-- 直接设置reduce个数为10
set mapreduce.job.reduces=10;
-- 执行以下语句,将数据均衡的分配到10个reduce中
insert overwrite table A partition(dt)
select * from B
distribute by rand();
解释:如设置reduce数量为10,则使用 rand() 随机生成一个数 x,并计算 x % 10,这样数据就会被随机且相对均匀地分发到10个Reduce中,从而生成10个大小相近的文件。
9. COUNT(DISTINCT) 和 GROUP BY
计算去重指标时,COUNT(DISTINCT col) 在数据量大或倾斜时性能较差,因为它通常只使用一个Reducer。可以转换为GROUP BY + COUNT的两阶段计算来优化。
-- 原始脚本
SELECT age, COUNT(DISTINCT user_id)
FROM user_table
GROUP BY age;
-- 优化脚本
SELECT age, COUNT(user_id)
FROM (
SELECT age, user_id
FROM user_table
GROUP BY age, user_id -- 第一阶段:按所有维度去重
) t
GROUP BY age; -- 第二阶段:按目标维度计数
注意事项:
GROUP BY方案会生成两个MapReduce Job,增加了I/O开销,仅在数据量巨大或存在明显倾斜时才有优势。- Hive 3.x版本后,通过
set hive.optimize.countdistinct=true;可以开启对COUNT(DISTINCT)的自动优化,它会将查询转换为多个阶段,并能处理数据倾斜,通常无需手动改写。
10. 核心参数调优
以下是一些常用的性能调优参数,建议根据具体场景进行配置。
聚合与分组优化
-
set hive.optimize.countdistinct=true;- 说明:开启对
count(distinct)的自动优化。Hive会自动将其转换为更高效的、包含多个Job的执行计划,以应对数据倾斜。
- 说明:开启对
-
set hive.map.aggr=true;- 说明:开启Map端部分聚合。默认值为
true。在Map阶段预先对数据进行聚合,可以显著减少shuffle阶段需要传输的数据量。
- 说明:开启Map端部分聚合。默认值为
-
set hive.groupby.skewindata = true;- 说明:当有数据倾斜的时候进行负载均衡。默认值为
false。开启后,生成的查询计划会有两个MapReduce任务。第一个MR Job中,Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
- 说明:当有数据倾斜的时候进行负载均衡。默认值为
Join 优化相关
-
set hive.auto.convert.join = true;- 说明:开启自动Map Join。Hive会根据表的大小,自动判断是否可以将一个表加载到内存中,在Map端完成Join操作。
-
set hive.mapjoin.smalltable.filesize=26214400;- 说明:设置被Hive认为是“小表”的大小阈值,默认为25MB。如果�表的大小低于此值,Hive会优先尝试使用Map Join。
任务执行与资源
-
set hive.exec.parallel=true;- 说明:打开任务并行执行。
-
set hive.exec.parallel.thread.number=16;- 说明:同一个SQL允许的最大并行度,默认值为8。默认情况下,Hive一次只会执行一个阶段。开启并行执行时,会把一个SQL语句中没有相互依赖的阶段并行去运行,这样可能使得整个Job的执行时间缩短,提高集群资源利用率。不过这当然得是在系统资源比较空闲的时候才有优势,否则没资源,并行也起不来。
文件与I/O优化
-
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;- 说明:设置Map端执行前合并小文件,将多个小文件打包成一个split进行处理,减少Map任务数量。
-
set hive.exec.compress.output=true;- 说明:设置Hive的查询结果输出是否进行压缩。
-
set mapreduce.output.fileoutputformat.compress=true;- 说明:设置MapReduce Job的最终结果输出是否使用压缩。
查询行为与优化器
-
set hive.mapred.mode=strict;- 说明:设置严格模式,默认值是
nonstrict(非严格模式)。严格模式下会禁止以下3种类型的查询,避免因不合理的SQL导致性能问题:- 对于查询分区表,
WHERE子句中必须包含分区限制条件。 - 使用
ORDER BY进行全局排序时,必须加上LIMIT限制数据查询条数。 - 禁止笛卡尔积查询。
- 对于查询分区表,
- 说明:设置严格模式,默认值是
-
set hive.cbo.enable=true;- 说明:开启基于成本的优化器(Cost-Based Optimizer, CBO)。默认值为
true。CBO可以根据表的统计信息(如行数、数据分布等),自动优化HQL中多个JOIN的顺序,并选择更合适的JOIN算法。
- 说明:开启基于成本的优化器(Cost-Based Optimizer, CBO)。默认值为
11. 解决数据倾斜问题
1. 什么是数据倾斜
数据倾斜的根本原因是key的分布不均。在shuffle阶段,相同key的数据被发送到同一个Reducer。如果某个或某几个key的数据量远超其他key,就会导致对应的Reducer负载极重、执行缓慢,而其他Reducer早已完成,最终拖慢整个任务。
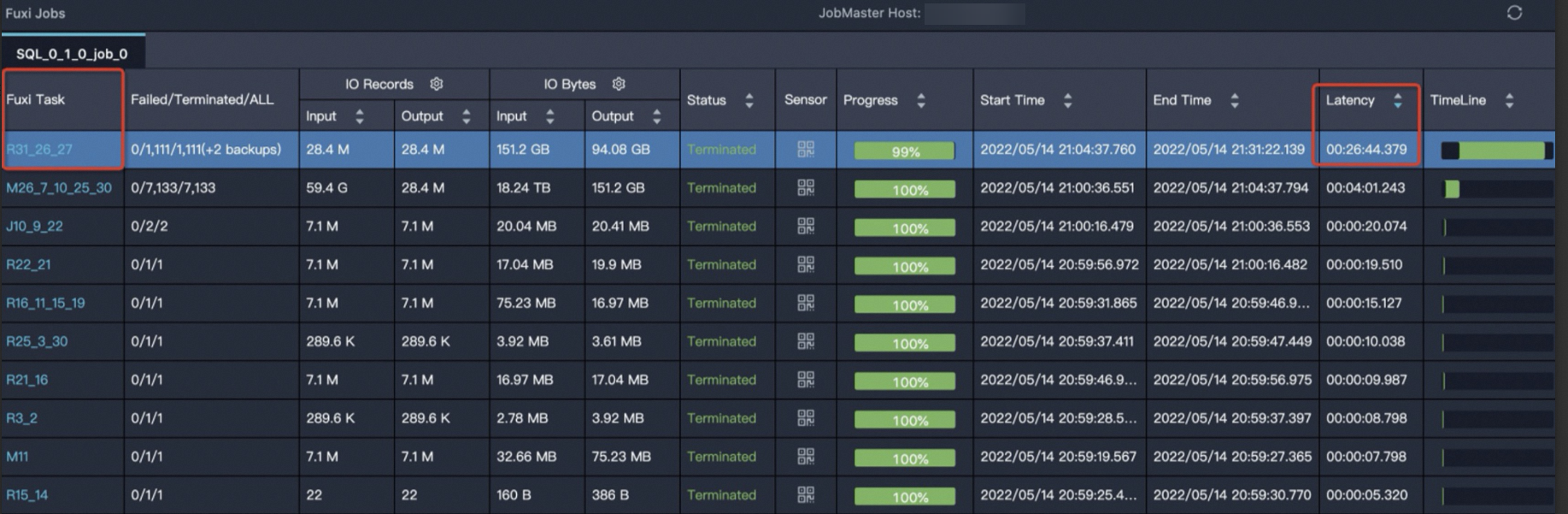
2. 数据倾斜的明显表现
- 任务进度长时间停留在99%(或某个Reduce的进度)。
- 通过YARN UI观察,发现大部分Task已完成,但少数几个Reduce Task迟迟没有结束。
- 任务日志中出现OOM(Out of Memory)错误。
3. 常见的数据倾斜场景
GROUP BY:分组的维度值分布不均。COUNT(DISTINCT):如前所述。JOIN:关联键存在大量NULL值或热点值。(小表Join大表 / 大表join大表)
4. 解决方案
大量经验表明,许多数据倾斜问题源于建表时的疏忽或可以通过业务逻辑规避。 解决数据倾斜的核心思想是设法将倾斜的数据打散,使其能够均匀地分布到��各个Reducer中。
1. 参数调优
set hive.map.aggr=true;:Map端聚合,提前减少数据量。set hive.groupby.skewindata=true;:针对GROUP BY倾斜的通用解决方案。当开启此参数时,Hive会启动两个MR Job。第一个Job将数据随机分发到Reducer做部分聚合,第二个Job再进行最终的合并聚合,从而实现负载均衡。
2. GROUP BY 与 COUNT(DISTINCT) 倾斜处理
当分组聚合操作发生倾斜时,可以采用以下SQL层面的技巧:
-
使用
SUM(...) + GROUP BY替代COUNT(DISTINCT): 当数据量巨大或分组维度基数较小时,COUNT(DISTINCT)容易产生倾斜。可以转换为两阶段聚合,即先使用内层GROUP BY对所有维度进行去重,再在外层进行COUNT或SUM。-- 优化前SELECT dimension, COUNT(DISTINCT user_id) FROM table GROUP BY dimension;-- 优化后SELECT dimension, COUNT(1) FROM (SELECT dimension, user_id FROM table GROUP BY dimension, user_id) tmp GROUP BY dimension; -
处理倾斜的特殊值(如NULL或空字符串):
-
隔离处理法:将导致倾斜的特殊值(如
NULL)单独过滤出来处理,剩余的正常数据进行常规聚合,最后将两部分结果UNION ALL合并。示例: 假设要统计订单表中不同
user_id的订单数,但存在大量user_id为NULL的游客订单。-- 优化前 (大量NULL值涌向一个Reducer,导致倾斜)SELECT user_id, COUNT(order_id) FROM orders GROUP BY user_id;-- 优化后 (将NULL值订单单独计算,再合并结果)-- 1. 计算非NULL用户的订单数 (这部分数据分布均匀,执行很快)SELECT user_id, COUNT(order_id)FROM ordersWHERE user_id IS NOT NULLGROUP BY user_idUNION ALL-- 2. 单独计算NULL用户的订单数 (通常只有一个结果,无需复杂聚合)SELECT NULL AS user_id, COUNT(order_id)FROM ordersWHERE user_id IS NULL; -
COUNT DISTINCT的特殊技巧:如果只是计算COUNT(DISTINCT),且倾斜键是NULL,可以先将其过滤掉,完成计算后,在最终结果上+1即可(前提是NULL也算作一个有效值)。示例: 统计总共有多少个不同的用户(包括游客
NULL用户)。-- 优化前 (大量NULL值导致COUNT DISTINCT倾斜)SELECT COUNT(DISTINCT user_id) FROM orders;-- 优化后 (先计算非NULL用户,结果再加1)-- 假设下面查询结果为 999999SELECT COUNT(DISTINCT user_id) FROM orders WHERE user_id IS NOT NULL;-- 最终结果手动或在应用层计算为 999999 + 1 = 1000000
-
3. Join 倾斜处理
-
空值或无效值导致的倾斜:处理方式与
GROUP BY类似,采用隔离处理法,将NULL键的记录和非NULL键的记录分开处理,最后UNION ALL。 -
不同数据类型关联:确保
JOIN的关联键数据类型完全一致。如果一个是int,另一个是string,应使用CAST函数统一为string类型。因为在Shuffle阶段,对Join Key进行哈希计算时,不同数据类型的相同值会产生不同的哈希结果,导致本应聚合到一起的数据被发往了不同的Reducer,而无法处理的类型则可能全部被发往同一个Reducer。 -
热点值处理(倾斜键):
-
拆分Join:将倾斜的key单独拿出来处理,然后将结果与非倾斜key的处理结果
UNION ALL。(示例同上文的隔离处理法) -
Map Join + 扩容小表(一箭双雕的“加盐”法): 这个技巧解决什么问题? 它一箭双雕,同时解决两个棘手问题:
-
数据倾斜:当某个Join Key(如某个大客户ID)的数据量远超其他Key时,导致计算任务分配不均。
-
Map Join内存瓶颈:当“小表”(如客户信息表)规模中等,无法完全加载进内存,导致无法使用最高效的Map Join。
核心思想:化整为零,分而治之 既然一次性处理一个大的Join会出问题,那么就把它拆分成N个小规模的Join并行处理。具体做法是:
-
打散大表:为大表的Join Key添加随机后缀(俗称“加盐”),将热点Key的数据随机、均匀地打散到N个新的Key上。
-
复制小表:将小表的每一行数据复制N份,并为每份打上与大表对应的后缀,确保数据能够正确关联。
-
场景示例: 假设我们需要将海量的
transaction_flow(交易流水表,极大)与customer_info(客户信息表,中等规模)进行关联,以分析每笔交易的风险。其中,某个大商户的customer_id造成了严重的数据倾斜。我们将任务拆分成10份来处理。SELECTtxn.*,cust.*FROM(-- 1. 为大表(交易流水)的Join Key“加盐”,实现随机打散SELECT *, CONCAT(customer_id, '_', floor(rand() * 10)) AS join_keyFROM transaction_flow) txnJOIN(-- 2. 将小表(客户信息)的每一行复制10份,并打上对应的“盐”SELECT *, CONCAT(customer_id, '_', num) AS join_keyFROM customer_info-- 使用explode技巧,为customer_info的每一行生成10行,num字段的值从0到9LATERAL VIEW EXPLODE(split('0,1,2,3,4,5,6,7,8,9',',')) t AS num) custON txn.join_key = cust.join_key;代码解读:
-
处理大表
transaction_flow:rand() * 10会生成一个0到10之间的随机浮点数。floor(...)将其向下取整,得到一个0到9的随机整数。CONCAT(...)将原始的customer_id和这个随机数拼接起来,形成新的join_key。- 效果:某个大客户ID下的海量交易被随机分配到10个不同的新Key上(例如
cust_id_0,cust_id_1...),实现了数据的均匀打散。
-
处理小表
customer_info:LATERAL VIEW EXPLODE(split(...))是一个强大的组合。split函数将字符串'0,1,...,9'变成一个数组,然后EXPLODE函数会将数组中的每个元素('0'到'9')都拿出来,与原始行数据组合,生成新的一行。- 效果:
customer_info表中的每一行都被复制成了十行,唯一的区别是它们分别被赋予了从_0到_9的后缀,生成了十个不同的join_key。
-
最终的
ON条件:ON txn.join_key = cust.join_key确保了被打上_7后缀的交易数据,只会去寻找同样被打上_7后缀的客户信息进行匹配。这样,一个大的Join就被逻辑上拆分成了10个并行的�小Join。
最终效果:
- 解决了数据倾斜:原先集中在单个大商户
customer_id上的百万笔交易,被随机均匀地分散到了10个不同的join_key上。计算压力被平均分摊,消除了性能瓶颈。 - 为Map Join创造了条件:原本整个
customer_info表可能过大无法加载,现在每个并行的“小Join”任务,理论上只需要加载customer_info表1/10的数据。内存压力骤减,使得执行高效的Map Join成为可能。 总结
-
-
让Map节点的输出数据更均匀地分布到Reduce节点中去,是解决数据倾斜的最终目标。
三、总结与最佳实践
-
养成数据收敛的习惯:在编写HiveQL时,应时刻将“提前过滤、减少数据量”作为第一原则,避免无用数据参与复杂计算。
-
避免过度优化:优化应针对瓶颈进行。不要在非性能瓶颈处投入过多精力,有时复杂的优化技巧可能带来维护成本的增加,得不偿失。
-
强调复用性:对于公共的、可复用的计算逻辑,应将其沉淀为中间模型表。这不仅能提升开发效率,也能保证数据口径的一致性。
-
理解底层原理:深入理解MapReduce执行原理、Hive的查询计划生成机制,是进行高级优化的基础。
-
理透业务需求:代码优化服务于业务,�清晰的业务需求是选择最合适优化策略的前提。
-
关注全局影响:
全局优才是优! 在进行参数调优时,尤其是在调整内存、CPU等资源相关参数时,必须谨慎评估其对整个集群的影响。避免因为个人任务的性能提升,而抢占过多公共资源,导致其他任务运行失败或变慢。