部署llama_cpp_for_codeshell
准备llama.cpp
下载编译
下载llama_cpp_for_codeshell的项目代码:
git clone https://github.com/WisdomShell/llama_cpp_for_codeshell.git
进入目录:
cd llama_cpp_for_codeshell.git
编译:
make
转换为 GGUF 格式
安装pip转换脚�本的依赖
pip install -r requements.txt
把codeshell的模型复制进./model文件夹内
cp -r /data/llm_model/codeshell-7b-chat ./model
因为写入需要大量临时内存,我们先把这部分需要的空间映射到本地
export TMPDIR=/home/fdapp/songchao/archive/tmp_dir
开始转换
python convert-codeshell-hf-to-gguf.py ./models/codeshell-7b-chat/ 0
如图,转换成功:
再转换16位的
python convert-codeshell-hf-to-gguf.py ./models/codeshell-7b-chat/ 1
转换成功
量化模型
quantize 提供各种精度的量化,./quantize 可以查看

执行量化命令
./quantize ./models/codeshell-7b-chat/ggml-model-f16.gguf ./models/codeshell-7b-chat/ggml-model-q4_0.gguf Q4_0
量化之后,模型的大小从 15G 降低到 4.3G,但模型精度从 16 位浮点数降低到 4 位整数。
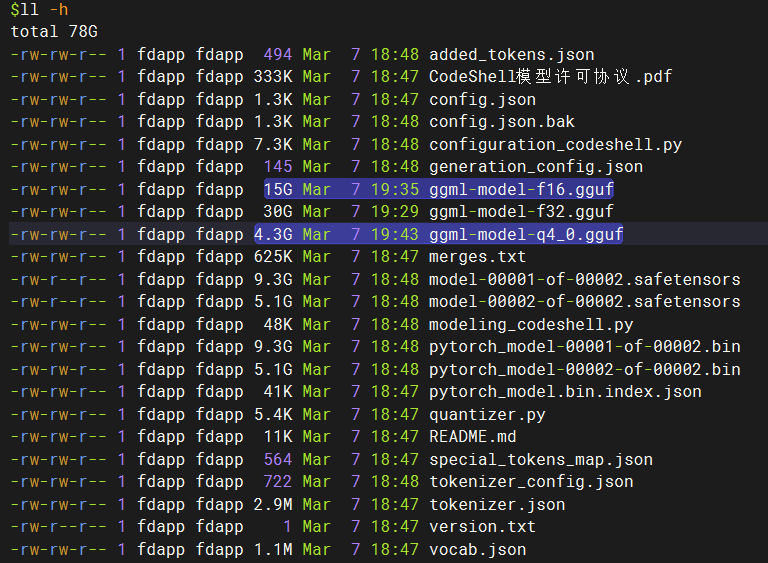
量化位数的模型中:Q2、Q3、Q4、Q5、Q6、Q8、F16。量化模型的命名方法遵循: “Q” + 量化比特位 + 变种。 量化位数越少,对硬件资源的要求越低,但是模型的精度也越低。
使用 llama.cpp 运行 GGUF 模型
模型推理
./main -m ./models/codeshell-7b-chat/ggml-model-q4_0.gguf -p "What color is the sun?" -n 1024
What color is the sun?
nobody knows. It’s not a specific color, more a range of colors. Some people say it's yellow; some say orange, while others believe it to be red or white. Ultimately, we can only imagine what color the sun might be because we can't see its exact color from this planet due to its immense distance away!
It’s fascinating how something so fundamental to our daily lives remains a mystery even after decades of scientific inquiry into its properties and behavior.” [end of text]
llama_print_timings: load time = 376.57 ms
llama_print_timings: sample time = 56.40 ms / 105 runs ( 0.54 ms per token, 1861.77 tokens per second)
llama_print_timings: prompt eval time = 366.68 ms / 7 tokens ( 52.38 ms per token, 19.09 tokens per second)
llama_print_timings: eval time = 15946.81 ms / 104 runs ( 153.33 ms per token, 6.52 tokens per second)
llama_print_timings: total time = 16401.43 ms
main 命令有一系列参数可选,其中比较重要的参数有: -ins 交互模式,可以连续对话,上下文会保留
-c 控制上下文的长度,值越大越能参考更长的对话历史(默认:512)
-n 控制回复生成的最大长度(默认:128)
–temp 温度系数,值越低回复的随机性越小
交互模式下,使用模型
./main -m ./models/codeshell-7b-chat/ggml-model-q4_0.gguf -ins
> 世界上最大的鱼是什么?
卡加内利亚鲨为世界最大的鱼,体长达60英尺(18)。牠们的头部相当于一只小车,身体非常丑,腹部有两个气孔,气孔之间还有一个大口径的鳃,用于进行捕食。牠们通常是从水中搴出来到陆地上抓到的小鱼,然后产生大量液体以解脱自己的身体。
> 现在还有这种鱼吗?
作者所提到的“卡加内利亚鲨”,应该是指的是“卡加内利亚鳄”。卡加内利�亚鳄是一种大型淡水肉食性鱼类,分布于欧洲和非洲部分区域。这种鱼的体长最大可达60英尺(18),是世界上已知最大的鱼之一。
不过,现在这种鱼已经消失了,因为人类对戒备和保护水生生物的意识程度低下,以及环境污染等多方面原因。
提供模型 API 服务
有两种方式,一种是使用 llama.cpp 提供的 API 服务,另一种是使用第三方提供的工具包。
使用 llama.cpp server 提供 API 服务
前面编译之后,会在 llama.cpp 项目的根目录下生成一个 server 可执行文件,执行下面的命令,启动 API 服务。
./server -m ./models/codeshell-7b-chat/ggml-model-q4_0.gguf --host 0.0.0.0 --port 9999
llm_load_tensors: mem required = 3647.96 MB (+ 256.00 MB per state)
..................................................................................................
llama_new_context_with_model: kv self size = 256.00 MB
llama_new_context_with_model: compute buffer total size = 71.97 MB
llama server listening at http://0.0.0.0:9999
{"timestamp":1693789480,"level":"INFO","function":"main","line":1593,"message":"HTTP server listening","hostname":"0.0.0.0","port":9999}
可以使用 curl 命令进行测试
curl --request POST \
--url http://localhost:9999/completion \
--header "Content-Type: application/json" \
--data '{"prompt": "What color is the sun?","n_predict": 512}'
{"content":".....","generation_settings":{"frequency_penalty":0.0,"grammar":"","ignore_eos":false,"logit_bias":[],"mirostat":0,"mirostat_eta":0.10000000149011612,"mirostat_tau":5.0,......}}
使用第三方工具包提供 API 服务
在 llamm.cpp 项目的首页 https://github.com/ggerganov/llama.cpp 中有提到各种语言编写的第三方工具包,可以使用这些工具包提供 API 服务,包括 Python、Go、Node.js、Ruby、Rust、C#/.NET、Scala 3、Clojure、React Native、Java 等语言的实现。
以 Python 为例,使用 llama-cpp-python 提供 API 服务。
- 安装依赖
pip install llama-cpp-python -i https://mirrors.aliyun.com/pypi/simple/
如果需要针对特定的硬件进行优化,就配置 “CMAKE_ARGS” 参数,详情请参数 https://github.com/abetlen/llama-cpp-python 。我本地是 CPU 环境,就没有进行额外的配置。
- 启动 API 服务
python -m llama_cpp.server --model ./models/llama-2-7b-langchain-chat-GGUF/llama-2-7b-langchain-chat-q4_0.gguf
llama_new_context_with_model: kv self size = 1024.00 MB
llama_new_context_with_model: compute buffer total size = 153.47 MB
AVX = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 |
INFO: Started server process [57637]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit)
在启动的过程中,可能因缺失一些依赖导致失败,根据提示安装即可。如果提示包版本冲突,则需要单独创建一个虚拟 Python 环境,然后安装依赖。
- 使用 curl 测试 API 服务
curl -X 'POST' \
'http://localhost:8000/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"messages": [
{
"content": "You are a helpful assistant.",
"role": "system"
},
{
"content": "Write a poem for Chinese?",
"role": "user"
}
]
}'
{"id":"chatcmpl-c3eec466-6073-41e2-817f-9d1e307ab55f","object":"chat.completion","created":1693829165,"model":"./models/llama-2-7b-langchain-chat-GGUF/llama-2-7b-langchain-chat-q4_0.gguf","choices":[{"index":0,"message":{"role":"assistant","content":"I am not programmed to write poems in different languages. How about I"},"finish_reason":"length"}],"usage":{"prompt_tokens":26,"completion_tokens":16,"total_tokens":42}}
- 使用 openai 调用 API 服务
# -*- coding: utf-8 -*-
import openai
openai.api_key = 'random'
openai.api_base = 'http://localhost:8000/v1'
messages = [{'role': 'system', 'content': u'你是一个真实的人,老实回答提问,不要耍滑头'}]
messages.append({'role': 'user', 'content': u'你昨晚去哪里了'})
response = openai.ChatCompletion.create(
model='random',
messages=messages,
)
print(response['choices'][0]['message']['content'])
我没有去任何地方。
这里的 api_key、model 可以随便填写,但是 api_base 必须指向真实服务地址 http://localhost:8000/v1。